Performance réseau
Le champ « Payload » de la trame Ethernet contient la donnée ayant été encapsulée en TCP ou UDP, puis en IP.
| Frame Component | TCP | UDP | ||
|---|---|---|---|---|
| Inter Frame Gap | 12 Bytes | 12 Bytes | ||
| MAC Preamble (+SFD) | 8 Bytes | 8 Bytes | ||
| MAC Destination Address | 6 Bytes | 6 Bytes | ||
| MAC Source Address | 6 Bytes | 6 Bytes | ||
| MAC Type (or length) | 2 Bytes | 2 Bytes | ||
| Payload (Network PDU)
46 – 1500 Bytes |
IPv4 Header | 20 Bytes | IPv4 Header | 20 Bytes |
| TCP Header | 20 Bytes | UDP Header | 8 Bytes | |
| TCP options / Data/Padding | 6 – 1460 Bytes | Data/Padding | 18 – 1472 Bytes | |
| Check Sequence (CRC) | 4 Bytes | 4 Bytes | ||
| Total Frame Physical Size | 84 – 1,538 Bytes | |||
|
Gigabit Ethernet TCP/IP & UDP/IP Throughput |
|
|---|---|
| Max TCP/IP Data Rate (84 Bytes Frames)
Min TCP/IP Packet (60 Bytes + 4 Bytes CRC) |
(1) ≈ 71 Mbps |
| Max TCP/IP Data Rate (1538 Bytes Frames)
Max TCP/IP Packet (1514 Bytes + 4 Bytes CRC) With TCP/IP TimeStamp |
(2) ≈ 941 Mbps |
| Max TCP/IP Data Rate (1538 Bytes Frames)
Max TCP/IP Packet (1514 Bytes + 4 Bytes CRC) Without TCP/IP TimeStamp |
(3) ≈ 949 Mbps |
| Max UDP/IP Data Rate (84 Bytes Frames)
Min UDP/IP Packet (60 Bytes + 4 Bytes CRC) |
(4) ≈ 214 Mbps |
| Max UDP/IP Data Rate (1538 Bytes Frames)
Max UDP/IP Packet (1514 Bytes + 4 Bytes CRC) |
(5) ≈ 957 Mbps |
(1) [latex]1,488,095 f/s \times 6 Bytes/Frame \times 8 b/B[/latex]
(2) [latex]81,274 f/s \times 1,448 Bytes/Frame \times 8 b/B[/latex]
(3) [latex]81,274 f/s \times 1,460 Bytes/Frame \times 8 b/B[/latex]
(4) [latex]1,488,095 f/s \times 18 Bytes/Frame \times 8 b/B[/latex]
(5) [latex]81,274 f/s \times 1,472 Bytes/Frame \times 8 b/B[/latex]
TCP (Transmission Control Protocol) et UDP (User Datagram Protocol) sont utilisés pour transférer des données ou des paquets sur les réseaux. TCP est orienté connexion tandis que UDP est sans connexion. La transmission TCP est plus fiable, mais plus lente car elle contrôle les erreurs et maintient l’ordre des données. UDP ne possède pas de mécanisme de contrôle d’erreur, c’est pourquoi il est moins fiable mais plus rapide dans le transfert de données.
Il existe plusieurs implémentations de TCP (Tahoe, Reno, Vegas, New Reno…), mais fondamentalement, le fonctionnement de TCP reste le même et s’appuie sur le RFC 5681. Il convient de connaître l’implémentation mise en œuvre sur le système utilisé et d’en changer s’il s’avère qu’il n’est pas le plus adapté à l’usage visé.
| TCP variant | Network | Class | Main features |
|---|---|---|---|
| Reno | Standard | Loss-based | Standard TCP |
| Vegas | Standard | Delay-based | Proactive scheme
RTT and rate estimation |
| Veno | Wireless | Delay-based | Combine Reno and Vegas
Deal with random loss |
| Westwood | Wireless | Delay-based | Deal with « Large » dynamic channels |
| BIC | Long fat[1] | Loss-based | Modification of congestion avoidance scheme |
| CUBIC | Long fat | Loss-based | Improved variant of BIC |
| HSTCP | Long fat | Loss-based | Modification of congestion avoidance scheme |
| Hybla | Long fat | Delay-based | Modification of congestion avoidance scheme |
| Scalable | Long fat | Loss-based | Modification of congestion avoidance scheme |
| Illinois | Long fat | Loss-Delay-based | Modification of congestion avoidance scheme |
| YeAH | Long fat | Delay-based | Two working modes for the congestion avoidance phase: fast and slow |
| HTCP | Long fat | Delay-based | Modification of congestion avoidance scheme |
| LP | – | Delay-based | Variant for low priority flows |
Il existe quatre algorithmes fondamentaux de contrôle de congestion : « slow start », « congestion avoidance », « fast retransmit » et « fast recovery ». Les algorithmes « slow start » et « congestion avoidance » doivent être utilisés par l’émetteur pour contrôler la quantité de donnée injectée dans le réseau. Pour implémenter ces algorithmes, deux variables sont utilisées : cwnd (sender side congestion window) et rwnd (receiver’s advertised window). La variable cwnd est la quantité de données que l’émetteur peut transmettre sur le réseau avant de recevoir un acquittement (ACK) et la variable rwnd est la limite côté récepteur. C’est le minimum de ces deux variables qui est pris comme référence dans la transmission de données. Une autre variable d’état : ssthresh (slow start threshold) est utilisée pour déterminer lequel des deux algorithmes « slow start » ou « congestion avoidance » doit être utilisé pour contrôler la transmission de données.
L’algorithme « slow start » est utilisé au démarrage ou après une perte détectée par le « retransmission timer », pour déterminer la capacité réseau disponible afin d’éviter une congestion. IW (Initial Window) est la valeur initiale de cwnd et doit être positionnée en utilisant les règles suivantes :
- Si « Sender MSS » > 2190 octets alors IW = 2 * SMSS octets et ne doit pas être supérieur à 2 segments
- Si (SMSS > 1095 octets) et (SMSS <= 2190 bytes) alors IW = 3 * SMSS octets et ne doit pas être supérieur à 3 segments
- Si SMSS <= 1095 octets alors IW = 4 * SMSS octets et ne doit pas être supérieur à 4 segments
La valeur initiale de ssthresh devrait être fixée à la taille de la plus large fenêtre possible (advertised window), mais ssthresh doit être réduit en réponse à la congestion. L’algorithme « slow start » est utilisé quand cwnd < ssthresh, alors que l’algorithme « congestion avoidance » est utilisé quand cwnd > ssthresh. En cas d’égalité, l’émetteur peut choisir l’algorithme à utiliser. Pendant la phase « slow start », TCP incrémente cwnd d’au plus SMSS octets et « slow start » s’arrête quand cwnd atteint ou dépasse ssthresh. Il est recommandé d’augmenter cwnd de la manière suivante :
[latex]cwnd += min (N, SMSS)[/latex]
avec N étant le nombre d’octets ayant été acquittés dans le dernier ACK.
Pendant la phase « congestion avoidance », cwnd est augmenté d’environ un segment par RTT (Round-Trip Time) et l’algorithme continue son travail jusqu’à ce qu’une congestion soit détectée. Il est recommandé d’augmenter cwnd de la manière suivante et d’effectuer un ajustement à chaque réception d’un ACK :
[latex]cwnd += SMSS \times \frac{SMSS}{cwnd}[/latex]
Quand un émetteur détecte la perte d’un segment à l’aide du « retransmission timer » et que ce segment n’a pas été réémis, la valeur de ssthresh ne doit pas être positionnée au delà de la valeur donnée par l’équation :
[latex]ssthresh = max (\frac{FlightSize}{2}, 2 \times SMSS)[/latex]
avec FlightSize étant la quantité de données en attente dans le réseau.
Un récepteur, en TCP, devrait envoyer immédiatement un « duplicate ACK » lorsqu’un segment « out-of-order » arrive, avec comme objectif d’informer l’émetteur sur ce qui s’est produit et demander à nouveau l’expédition du segment. L’émetteur devrait utiliser l’algorithme « fast retransmit » pour détecter et réparer la perte en se basant sur les « duplicate ACKs » entrants. L’algorithme utilise l’arrivée de trois « duplicate ACKs » comme indication qu’un segment a été perdu. Dès lors, TCP effectue une retransmission du segment perdu sans attendre l’expiration du « retransmission timer ». Après la transmission du segment perdu, l’algorithme « fast recovery » prend en charge la transmission des nouvelles données jusqu’à ce qu’un « non-duplicate ACK » arrive. L’implémentation des algorithmes « fast retransmit » et « fast recovery » suit des règles de positionnement de valeurs pour cwnd et ssthresh.
De façon simplifiée, le débit TCP est calculé avec la formule suivante :
[latex]Throughput = \frac{Window Size}{RTT}[/latex]
Des études ont prouvé qu’il était nécessaire de prendre en compte d’autres paramètres comme le MSS (Maximum Segment Size) et la perte de paquet. Comme expliqué dans [0], en partant du principe que le réseau a une probabilité de perte de paquet appelée p, l’émetteur sera capable d’envoyer une moyenne de [latex]\frac{1}{p}[/latex] paquets avant une perte de paquet. Selon ce modèle, cwnd n’excédera jamais un maximum W (fenêtre exprimant le nombre de segments pouvant être émis durant un RTT), car à approximativement [latex]\frac{1}{p}[/latex] paquets, une nouvelle perte de paquet va provoquer la division par deux de cwnd. De ce fait, la quantité totale de donnée délivrée à chaque cycle de [latex]\frac{1}{p}[/latex] paquets est donnée par :
[latex]\frac{1}{p} = \left( \frac{W}{2} \right) ^2 + \frac{1}{2} \left( \frac{W}{2} \right) ^2 = \frac{3}{8} W^2[/latex]
Par conséquent, [latex]MSS \times \frac{3}{8} W^2[/latex] octets sont émis à chaque cycle de [latex]RTT \times \frac{W}{2}[/latex].
Comme [latex]W = \sqrt{\frac{8}{3p}}[/latex] le débit est donc de :
[latex]Throughput = \frac{MSS \times \frac{3}{8} W^2}{RTT \times \frac{W}{2}} = \frac{\frac{MSS}{p}}{RTT \sqrt{\frac{2}{3p}}}[/latex]
[latex]Throughput =\frac{MSS \times \sqrt{\frac{3}{2}}}{RTT \times \sqrt{p}} = \frac{MSS \times 1,22}{RTT \times \sqrt{p}}[/latex]
Une étude [1] a comparé différentes implémentations de TCP et a mis en évidence les différences de performances dans des situations où les valeurs de RTT et de probabilité de perte varient. Il en résulte que sur un réseau filaire, les implémentations TCP Hybla et TCP CUBIC obtiennent de très bonnes performances alors que TCP Reno tire aussi son épingle du jeu, mais que TCP-LP obtient les plus mauvais résultats. Sur un réseau sans-fil, les cartes sont redistribuées et ce sont les implémentations TCP Reno, TCP BIC et TCP-LP qui obtiennent les meilleurs résultats. Sur les réseau longue distance avec du retard, comme les réseaux satellites, c’est l’implémentation TCP CUBIC qui se comporte le mieux. Finalement, l’implémentation qui semble se comporter de façon homogène en toutes circonstances reste TCP Reno.
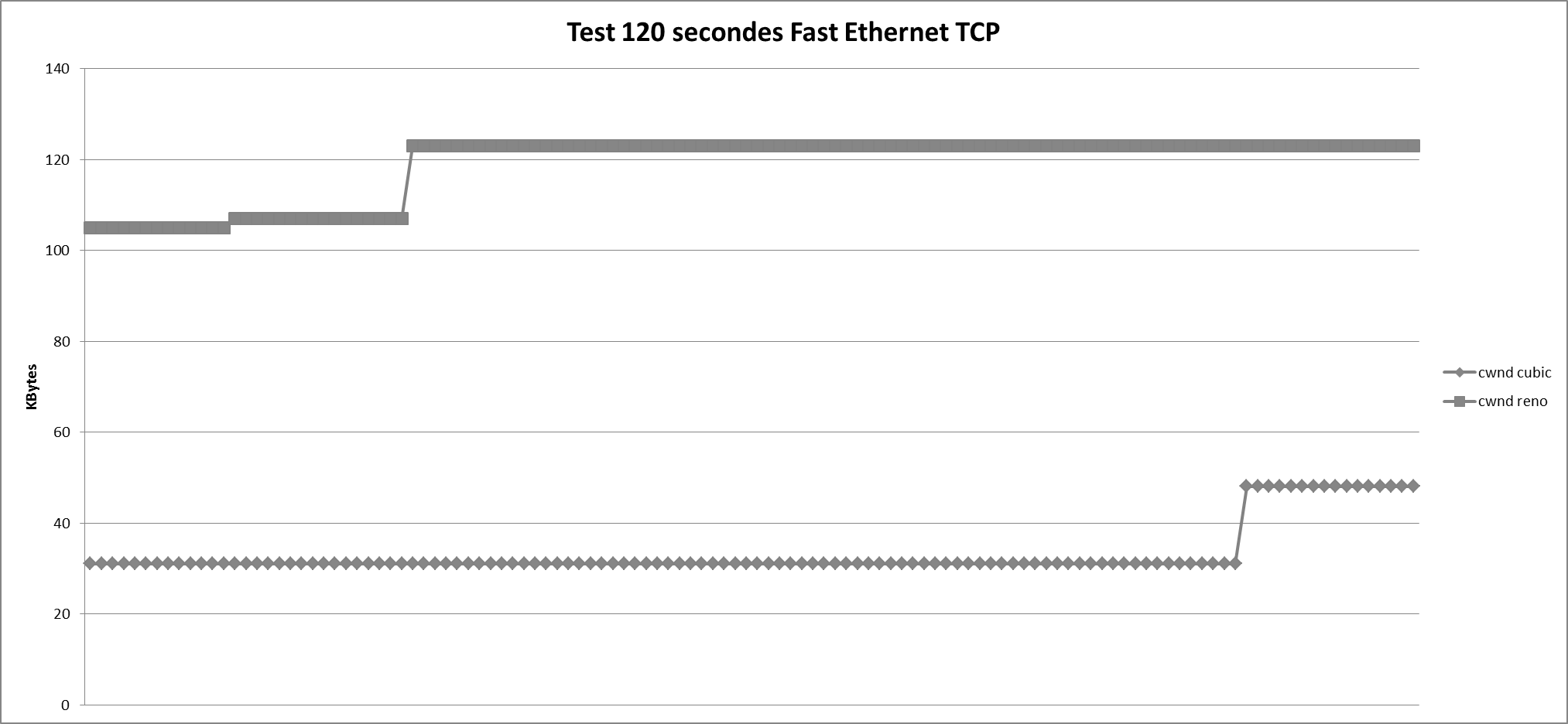
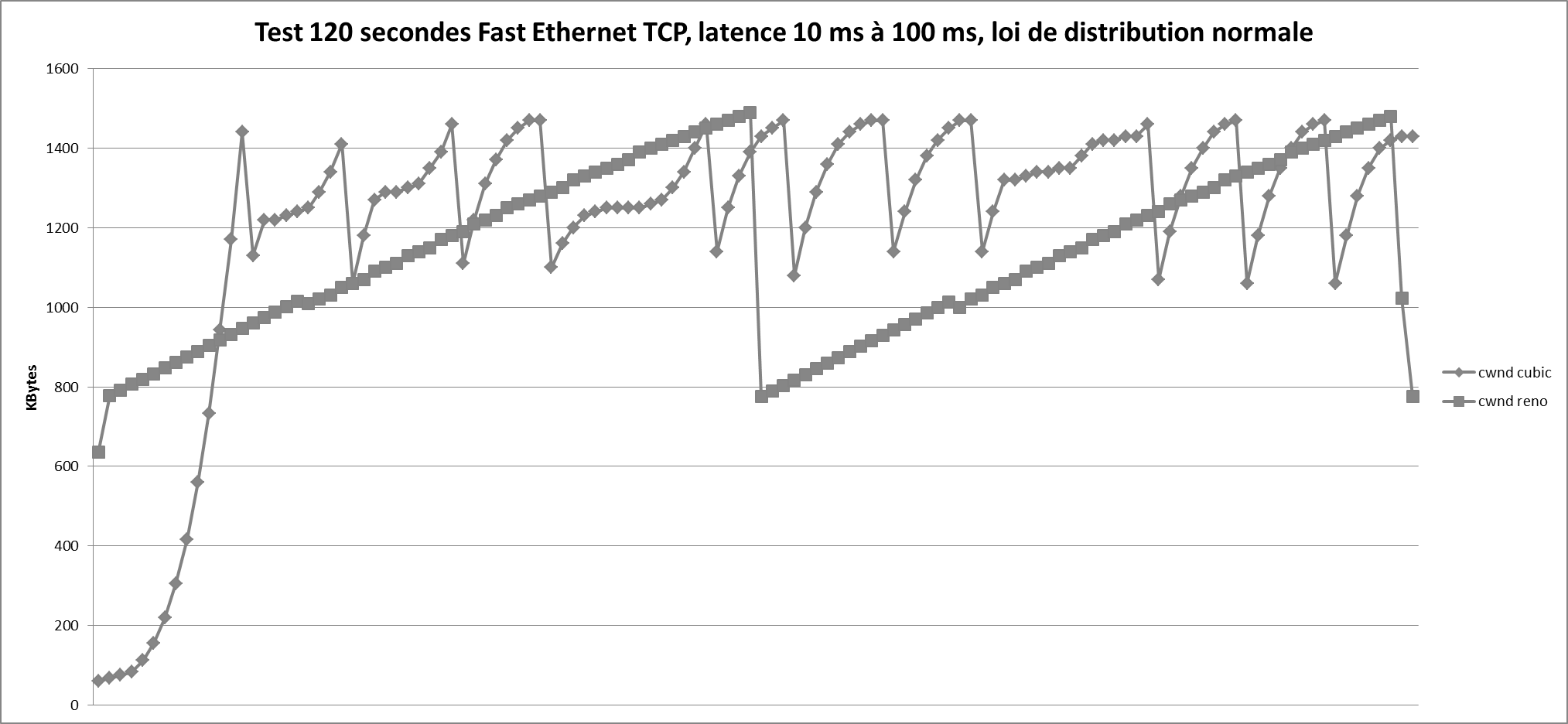
Les tests ci-dessus ont été réalisés entre deux Raspberry Pi montés avec Archlinux ARM. Les deux implémentations TCP (Cubic et Reno) ont été utilisées, dans un premier temps, avec une liaison Fast Ethernet standard. Dans un deuxième temps, les mesures ont été effectuées en induisant une latence variable de 10 millisecondes à 100 millisecondes, avec une variation suivant une loi de distribution normale. La latence a été introduite à l’aide de la fonctionnalité de contrôle de trafic présente dans le noyau de Linux. La loi normale est l’une des lois de probabilité les plus adaptées pour modéliser des phénomènes naturels issus de plusieurs événements aléatoires. Elle est également appelée loi gaussienne, loi de Gauss ou loi de Laplace-Gauss. Laplace et Gauss étaient deux mathématiciens qui ont étudié la loi normale. La représentation la plus connue de cette loi est la courbe de Gauss ou courbe en cloche.
Les analyses sur les impacts des implémentations TCP peuvent être réalisées sur un réseau avec des machines configurées de façon appropriée. Plus généralement, les études théoriques sur ces sujets se font avec des simulateurs de façon à faire abstraction des évènements non maîtrisés qui pourraient engendrer des réactions inattendues de la part des implémentations des algorithmes. Cependant, comme expliqué dans [2], il convient de prendre les outils de simulation pour ce qu’ils sont et ne pas considérer leurs résultats comme une preuve absolue.
- High Latency ↵
